
(Ich glaube, ich bin im falschen Unterforum gelandet... falls ja, bitte verschieben ;) )
Huhu ZFX'ler! :D
Ich würde mal gerne Wissen, wie ich maximale Rechengeschwindigkeit bekomme.
Mir schweben da Dinge wie Landschaftsberechnungen oder auch für Software Renderer im Kopf rum.
Nehmen wir erstmal die Grafikkarte, die extreme Rechenleistung im Vergleich zur CPU aufbringen kann, durch das Parallele abarbeiten von vielen Pixeln. Nun möchte ich aber die Daten auch irgendwie auf die CPU zurück bringen. Unter DX9 ist das nur sehr eingeschränkt möglich. Damals hab ich das ja schon mal zum zurück lesen von Clustern gemacht und da es wohl Treiber abhängig ist, und man das ganze nicht Asynchron machen kann, beliefen sich die Zeiten so um die 50-200 ms... mit OpenGL soll das ja wesentlich schneller sein, da schweben mir so Zeiten wie 7-10 ms im Kopf rum, ohne das jetzt selbst getestet zu haben... nur so vom Hörensagen ;)
Okay, auf der einen Seite haben wir die extrem schnelle GPU... nun, warum dann überhaupt noch die CPU? Meiner Meinung nach, weil man so auch für kleinere Berechnungen nie unter diese Rücklesezeit kommen kann. Und ich vermute, dass man prinzipiell auf der CPU wesentlich besser optimieren kann. So kann man z.B. wenn man ein Bild berechnet je nach Detail oder Werte Abbruchbedingungen Setzen. Jedes IF kann helfen, die Ausführung schneller zu machen.
Also im Moment teste ich ein bisschen rum und das erstmal auf der CPU.
Aber auch hier gibt es wieder viele Möglichkeiten. Aber bevor ich auf exotische Dinge wie Multithreading gehe, würde ich gerne im Single Core maximale Geschwindigkeit erreichen.
Dabei kommen mir die SSE2 Instructions und Dinge, zumindest unter Turbo Delphi 2006 etwas Umständlich vor. Z.B. müssen diese richtig im Speicher ausgerichtet werden.
Letztendlich verhelfen diese mir ja dazu, Berechnungen auch wieder Parallel auszuführen, Vektoren oder sonstwas. Nun, okay, also behalte ich mal im Hinterkopf, dass man bei Gleitkommaberechnungen noch einen Faktor von 4 oder so hat. Aber wie ist es nun sonst? Wie haben Spiele in den 90igern so viel aus nem 66MHz Rechner raus holen können?!
Warum kann er hier auf einem 16 MHz Atari ein HL1 Level (zwar in geringer Auflösung) aber texturiert mit 8 FPS darstellen?!
[youtube]WpwlZgQPCpk[/youtube]
Ich habe das Gefühl, ich weiß gar nichts, John Schnee! :D
Oder ist es immer noch schneller, wenn man auf Gleitkomma komplett verzichtet? Aber was gibt es da? Fixkomma? Oder direkt Integer? Bitte sagt mir, was ich tun kann um endlich meine 4 GHz auch wirklich nutzen zu können!!! :D
Maximale Rechenleistung
-
Krishty

- Establishment
- Beiträge: 8238
- Registriert: 26.02.2009, 11:18
- Benutzertext: state is the enemy
- Kontaktdaten:
Re: Maximale Rechenleistung
Einen vernünftigen Profiler runterladen, der dir pro Zeile Statistiken wie L1-Misses anzeigt!
-
Matthias Gubisch
- Establishment
- Beiträge: 470
- Registriert: 01.03.2009, 19:09
Re: Maximale Rechenleistung
1. Multithreading ist heutzutage nix exotisches mehr sondern schon fast ein muss für effizente Programmierung
2. Warum überhaupt noch CPU: ganz einfach weil du auf Grafikkarten zwar viele parallele Kerne hast, die aber lange nicht so viel können wie die CPU
3. Rechenleistung und Speicher war zur damaligen Zeit sehr teuer, da war es durchaus rentabel viel zeit in effizente Algorithmen und Datenstrukturen zu stecken. Heutzutage ist es eher so dass die Hardware billig ist, die Arbeitszeit der Entwickler allerdings teuer deshalb werden schon mal nicht ganz so effizente Implementierungen in kauf genommen da die Hardware ja billig ist.
4. Betriebssystem und Treiber Overhead, ich bin mir nicht sicher aber gefühlt hatte so ein OS früher etwas weniger Overhead als heute, hab das allerdings noch nie irgendwie getestet oder gar Gebenchmarkt.
5. Jedes IF kann halfen die Ausführung schneller zu machen: Diese Aussage halte ich führ gefährlich. Man muss sehr genau überlegen wie man die Abbruchbedingung setzt, da man ansonsten wenn es blöd läuft die Pipeline der CPU zusammenbrechen lässt und diese dann erst wieder neu gefüllt wird was grundsätzlich eine Verzögerung nach sich zieht. Je mehr Stages die Pipeline hat desto größter die Verzögerung.
2. Warum überhaupt noch CPU: ganz einfach weil du auf Grafikkarten zwar viele parallele Kerne hast, die aber lange nicht so viel können wie die CPU
3. Rechenleistung und Speicher war zur damaligen Zeit sehr teuer, da war es durchaus rentabel viel zeit in effizente Algorithmen und Datenstrukturen zu stecken. Heutzutage ist es eher so dass die Hardware billig ist, die Arbeitszeit der Entwickler allerdings teuer deshalb werden schon mal nicht ganz so effizente Implementierungen in kauf genommen da die Hardware ja billig ist.
4. Betriebssystem und Treiber Overhead, ich bin mir nicht sicher aber gefühlt hatte so ein OS früher etwas weniger Overhead als heute, hab das allerdings noch nie irgendwie getestet oder gar Gebenchmarkt.
5. Jedes IF kann halfen die Ausführung schneller zu machen: Diese Aussage halte ich führ gefährlich. Man muss sehr genau überlegen wie man die Abbruchbedingung setzt, da man ansonsten wenn es blöd läuft die Pipeline der CPU zusammenbrechen lässt und diese dann erst wieder neu gefüllt wird was grundsätzlich eine Verzögerung nach sich zieht. Je mehr Stages die Pipeline hat desto größter die Verzögerung.
Bevor man den Kopf schüttelt, sollte man sich vergewissern einen zu haben
-
Krishty
- Establishment
- Beiträge: 8238
- Registriert: 26.02.2009, 11:18
- Benutzertext: state is the enemy
- Kontaktdaten:
Re: Maximale Rechenleistung
Ryg hat übrigens eine tolle Artikelserie über schnelle Software-Rasterisierung:
https://fgiesen.wordpress.com/2013/02/1 ... ing-index/
Aber wie gesagt, hol dir 'nen vernünftigen Profiler!
https://fgiesen.wordpress.com/2013/02/1 ... ing-index/
Aber wie gesagt, hol dir 'nen vernünftigen Profiler!
-
xq

- Establishment
- Beiträge: 1581
- Registriert: 07.10.2012, 14:56
- Alter Benutzername: MasterQ32
- Echter Name: Felix Queißner
- Wohnort: Stuttgart & Region
- Kontaktdaten:
Re: Maximale Rechenleistung
Wenn du die GPU für generelle Berechnungen nutzen willst, nimm OpenCL. Die API ist gut dokumentiert und die Rücklesezeiten sind genauso hoch die die Schreibzeiten. Du hast sogar Interop zu OpenGL und DirectX, ob zu 9 weiß ich grade nicht.
Ansonsten programmiert sich das ähnlich zu Shadern, du hast aber auch die Option, das ganze zum Beispiel auf einer CPU zu parallelisieren, was auch da einen massiven Performanceboost mit sich bringt.
Ansonsten programmiert sich das ähnlich zu Shadern, du hast aber auch die Option, das ganze zum Beispiel auf einer CPU zu parallelisieren, was auch da einen massiven Performanceboost mit sich bringt.
War mal MasterQ32, findet den Namen aber mittlerweile ziemlich albern…
Programmiert viel in Zig und nervt Leute damit.
Zig und nervt Leute damit.
Programmiert viel in
 Zig und nervt Leute damit.
Zig und nervt Leute damit.-
dot

- Establishment
- Beiträge: 1734
- Registriert: 06.03.2004, 18:10
- Echter Name: Michael Kenzel
- Kontaktdaten:
Re: Maximale Rechenleistung
@warum CPU, Kurzfassung: GPU und CPU implementieren grundverschiedene Hardwarearchitekturen die jeweils für grundverschiedene Dinge optimiert sind, die Stärken der einen liegen genau dort, wo die Schwächen der anderen liegen. Eine CPU versucht, die Latenz eines Fingerhutes voller unabhängiger Berechnungen zu minimieren, eine GPU versucht, den Throughput eines Schwimmbeckens voller unabhängiger Berechnungen zu maximieren...
Bezüglich single-core Performance optimieren möchte ich dein Augenmerkt auf folgenden Plot (von hier) lenken:
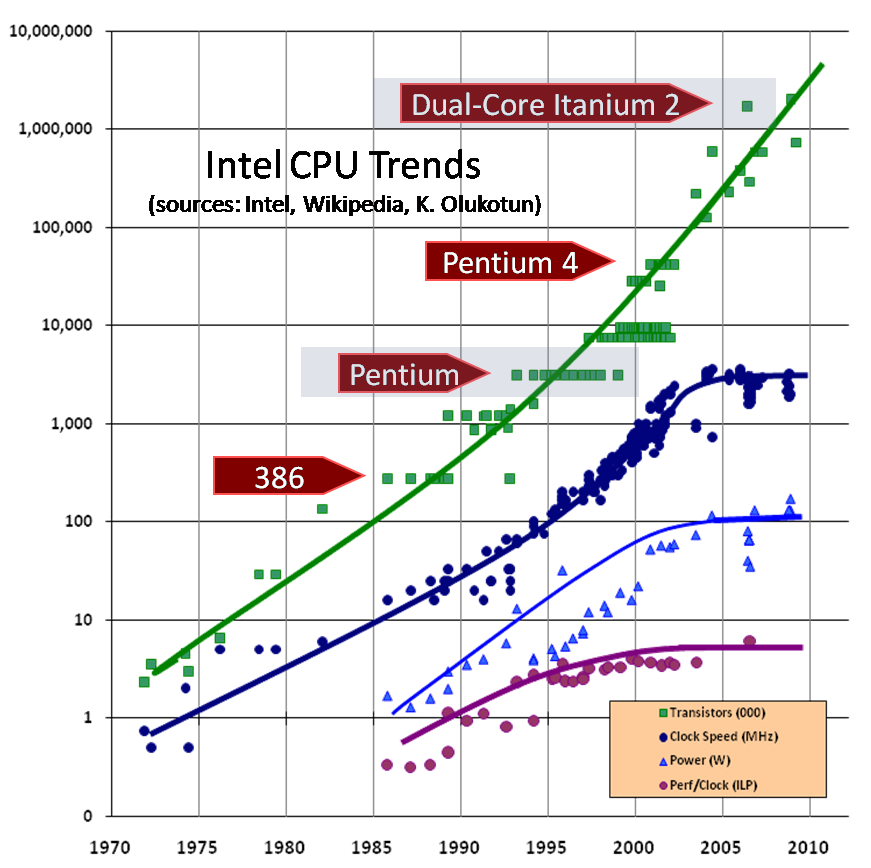
Beim optimieren der single-core Performance bist du effektiv an die blauen Kurven gebunden (aka: no matter how much time you spend, there's only so much you can possibly do), mit Multithreading profitierst du von der grünen. Was macht wohl mehr Sinn: Stunden um Stunden um Stunden in Profiling und low-level Optimierung investieren, um vielleicht noch die letzten paar Mikrosekunden rauszuholen, oder alles einfach 3x schneller machen? ;)
Bezüglich single-core Performance optimieren möchte ich dein Augenmerkt auf folgenden Plot (von hier) lenken:
Beim optimieren der single-core Performance bist du effektiv an die blauen Kurven gebunden (aka: no matter how much time you spend, there's only so much you can possibly do), mit Multithreading profitierst du von der grünen. Was macht wohl mehr Sinn: Stunden um Stunden um Stunden in Profiling und low-level Optimierung investieren, um vielleicht noch die letzten paar Mikrosekunden rauszuholen, oder alles einfach 3x schneller machen? ;)
-
Schrompf

- Moderator
- Beiträge: 4854
- Registriert: 25.02.2009, 23:44
- Benutzertext: Lernt nur selten dazu
- Echter Name: Thomas Ziegenhagen
- Wohnort: Dresden
- Kontaktdaten:
Re: Maximale Rechenleistung
Ansonsten kann man das so pauschal nicht sagen, was Code "schneller" macht. Nach meiner Erfahrung lohnt es sich, wenn man in minimalen Aufgaben denkt, die alle nötigen Daten reingereicht bekommen und isoliert arbeiten können. Je nach Möglichkeit können die außerdem eine lokale Kopie davon anlegen, damit die Caches warm bleiben. Und dann performen Aufgaben am Besten, die linear durch einen ganzen Satz Daten durchblasen können.
Beispiel:
Bei den Splitterwelten bin ich mit so ner Art Visitor-Pattern durch die Objekte durch, habe deren Sichtbarkeit geprüft und dann ein manchmal komplexes Gerassel an Bedingungen geprüft, um einen DrawCall abzusetzen.
Beim Voxelprojekt jetzt blase ich mit einem Visit 0 bis potentiell hunderte DrawCalls in eine Liste, habe dann eine Aufgabe, die mir ein Array aus BoundingBoxes berechnet, eine Aufgabe pro RenderPass, die mir diese BBs gegen das jeweilige Frustum prüft und nur ein Bitmuster in ein paar Dutzend uint64 schreibt, um am Ende dann die DrawCalls runterzuackern, falls das Sichtbar-Bit gesetzt ist.
Zweiteres lässt sich nicht nur kleingranular parallelisieren, sondern nutzt auch die spezifischen Eigenschaften aktueller Prozessoren aus, die trotz aller Optimierungen immer noch zufriedener sind, wenn sie linear große Datenmengen verwursten, als wenn sie tausend Einzelfälle betrachten müssen.
Dein Landschaftsgenerator ... nuja, Du solltest das unbedingt profilen, bevor Du irgendwas tust. Ich würde nämlich vermuten, die Mesh-Erstellung aus den Terraindaten ist das eigentlich Anstrengende. Machst Du das eigentlich auch auf der GPU? Über das Gespann CPU-GPU lässt sich nämlich primär sagen, dass es am besten läuft, wenn man es als Einbahnstraße betrachtet. Und das wird auch mit DX12 und Vulkan noch so bleiben, weil nunmal Deine Befehle an den Treiber nicht sofort ausgeführt werden, sondern in ner Warteschlange landen. Was Du auf dem Bildschirm siehst, ist potentiell zwei drei Frames hinter dem Stand auf der CPU hinterher. Und sobald Du das Ergebnis eines Treiber-Aufrufs auf der CPU brauchst, musst Du also diese zwei drei Frames warten, bis Du es kriegen kannst. Deine Landschaftserzeugung auf der GPU ist also eher tödlich als nützlich, wenn Du danach die Ergebnisse wieder zurücklesen musst. Und das musst Du ja, wenn Du auch nur ausrechnen willst, worauf der Spieler steht.
Beispiel:
Bei den Splitterwelten bin ich mit so ner Art Visitor-Pattern durch die Objekte durch, habe deren Sichtbarkeit geprüft und dann ein manchmal komplexes Gerassel an Bedingungen geprüft, um einen DrawCall abzusetzen.
Beim Voxelprojekt jetzt blase ich mit einem Visit 0 bis potentiell hunderte DrawCalls in eine Liste, habe dann eine Aufgabe, die mir ein Array aus BoundingBoxes berechnet, eine Aufgabe pro RenderPass, die mir diese BBs gegen das jeweilige Frustum prüft und nur ein Bitmuster in ein paar Dutzend uint64 schreibt, um am Ende dann die DrawCalls runterzuackern, falls das Sichtbar-Bit gesetzt ist.
Zweiteres lässt sich nicht nur kleingranular parallelisieren, sondern nutzt auch die spezifischen Eigenschaften aktueller Prozessoren aus, die trotz aller Optimierungen immer noch zufriedener sind, wenn sie linear große Datenmengen verwursten, als wenn sie tausend Einzelfälle betrachten müssen.
Dein Landschaftsgenerator ... nuja, Du solltest das unbedingt profilen, bevor Du irgendwas tust. Ich würde nämlich vermuten, die Mesh-Erstellung aus den Terraindaten ist das eigentlich Anstrengende. Machst Du das eigentlich auch auf der GPU? Über das Gespann CPU-GPU lässt sich nämlich primär sagen, dass es am besten läuft, wenn man es als Einbahnstraße betrachtet. Und das wird auch mit DX12 und Vulkan noch so bleiben, weil nunmal Deine Befehle an den Treiber nicht sofort ausgeführt werden, sondern in ner Warteschlange landen. Was Du auf dem Bildschirm siehst, ist potentiell zwei drei Frames hinter dem Stand auf der CPU hinterher. Und sobald Du das Ergebnis eines Treiber-Aufrufs auf der CPU brauchst, musst Du also diese zwei drei Frames warten, bis Du es kriegen kannst. Deine Landschaftserzeugung auf der GPU ist also eher tödlich als nützlich, wenn Du danach die Ergebnisse wieder zurücklesen musst. Und das musst Du ja, wenn Du auch nur ausrechnen willst, worauf der Spieler steht.
Früher mal Dreamworlds. Früher mal Open Asset Import Library. Heutzutage nur noch so rumwursteln.
-
dot
- Establishment
- Beiträge: 1734
- Registriert: 06.03.2004, 18:10
- Echter Name: Michael Kenzel
- Kontaktdaten:
Re: Maximale Rechenleistung
Mit Vulkan und D3D12 ist das nur so, wenn du es selbst so machst, der Driver tut da nix mehr automatisch Resource-Versioning betreiben und so, das ist genau die Art von Overhead, der rausgeflogen ist... ;)Schrompf hat geschrieben:Und das wird auch mit DX12 und Vulkan noch so bleiben, weil nunmal Deine Befehle an den Treiber nicht sofort ausgeführt werden, sondern in ner Warteschlange landen. Was Du auf dem Bildschirm siehst, ist potentiell zwei drei Frames hinter dem Stand auf der CPU hinterher.
-
Schrompf
- Moderator
- Beiträge: 4854
- Registriert: 25.02.2009, 23:44
- Benutzertext: Lernt nur selten dazu
- Echter Name: Thomas Ziegenhagen
- Wohnort: Dresden
- Kontaktdaten:
Re: Maximale Rechenleistung
Jupp. Du kannst dann halt sofort nach dem DrawCall den Inhalt des Rendertargets lesen. :) Du musst halt nur wissen, dass zu dem Zeitpunkt da nur Grütze drinsteht und selbst auf irgendner Barriere warten, bis der DrawCall durch ist.dot hat geschrieben:Mit Vulkan und D3D12 ist das nur so, wenn du es selbst so machst, der Driver tut da nix mehr automatisch Resource-Versioning betreiben und so, das ist genau die Art von Overhead, der rausgeflogen ist... ;)Schrompf hat geschrieben:Und das wird auch mit DX12 und Vulkan noch so bleiben, weil nunmal Deine Befehle an den Treiber nicht sofort ausgeführt werden, sondern in ner Warteschlange landen. Was Du auf dem Bildschirm siehst, ist potentiell zwei drei Frames hinter dem Stand auf der CPU hinterher.
Früher mal Dreamworlds. Früher mal Open Asset Import Library. Heutzutage nur noch so rumwursteln.
Re: Maximale Rechenleistung
Danke für eure vielen Antworten. Was nicht heißt, dass ich den Redefluss hier abreißen lassen möchte, ganz im Gegenteil! Es bringt nämlich viele Denkanstöße.
@Krishty
Dein Vorschlag ist sinnvoll, aber blöderweise suche ich mich da bestimmt tot für Delphi und ich bin voller Tatendrang und gar nicht angetan davon, so einen Profiler zum laufen zu bekommen und mich dann da einzuarbeiten... es geht mir auch grundsätzlich eher um die allgemeine Richtung.
@dot
Wenn ich jetzt nicht Schrompfs letzte Zeilen gelesen hätte, wäre ich jetzt definitiv entschlossen, es mit der CPU komplett zu lassen. Mir erscheint die Grafikkartenprogrammierung nämlich intuitiver und einfacher. Und ich glaube, dass man dann somit da doch wesentlich mehr rausholen kann.
@MasterQ32
Nach kurzer Recherche würde ich sagen, OpenGL ist für mich dann mittel zur Wahl. Einfach weil ich gar nicht weiß, wie es mit der OpenCL Unterstützung genau aussieht und dann unter Delphi wieder. Da ist mir lieber, von DX9 auf OpenGL umzusatteln.
@Schrompf
Ja meine Implementierungen damals, die Welt auf der GPU zu generieren waren erschütternd. Das brachte mir eher Lags als alles andere... das Problem ist bei DX9, dass man nicht Async zurück lesen kann. Bei den Occlusion Queries geht das ja noch, aber bei dem RT holen, da muss man entweder glück haben, dass es fertig ist, oder man bekommt nen Lag reingehauen. Und manchmal haben 200 ms Wartezeit zwischendurch nicht ausgereicht um sicher zu gehen beim erstellen. Und da ich auf CPU in ähnlichen Zeiten lag, hab ich schon seit Jahren die Cluster Erstellung wieder auf CPU, allerdings MT. Klappt auch soweit ganz gut. Außer dass ich Cachen muss, weil das erstellen so langsam ist... zumal mit AO Berechnungen mir das nicht gerade einen Geschwindigkeitszuwachs bringt. Allerdings würde ich nun nochmal probieren, wie es sich mit OpenGL verhält.
Deinen Ansatz finde ich extrem gut. Und solange ich bei Shadern bin, kann ich mir das gut vorstellen mit den kleinen Aufgaben. Aber sobald ich auf der CPU arbeite krüppel ich mir da einen zusammen.
Momentan überlege ich auch, ob ich vielleicht auf lange Sicht eine reine GPU Lösung tendiere, so dass man gar nicht mehr auf CPU zurücklesen muss... sollte ja eigentlich gehen, wenn man die Eingabe über Konstanten rein gibt und dann auch die Logik und Physik komplett auf GPU läuft. Ich muss mich nur überwinden und trauen, diese ganzen Schritte zu gehen.
@dot
Ach jetzt fällt mir erst auf, dass das Bild ja logarithmisch ist... ja das ist dann natürlich extrem krass, wenn man sich das in linearer Darstellung vorstellt! :D
@Krishty
Dein Vorschlag ist sinnvoll, aber blöderweise suche ich mich da bestimmt tot für Delphi und ich bin voller Tatendrang und gar nicht angetan davon, so einen Profiler zum laufen zu bekommen und mich dann da einzuarbeiten... es geht mir auch grundsätzlich eher um die allgemeine Richtung.
@dot
Wenn ich jetzt nicht Schrompfs letzte Zeilen gelesen hätte, wäre ich jetzt definitiv entschlossen, es mit der CPU komplett zu lassen. Mir erscheint die Grafikkartenprogrammierung nämlich intuitiver und einfacher. Und ich glaube, dass man dann somit da doch wesentlich mehr rausholen kann.
@MasterQ32
Nach kurzer Recherche würde ich sagen, OpenGL ist für mich dann mittel zur Wahl. Einfach weil ich gar nicht weiß, wie es mit der OpenCL Unterstützung genau aussieht und dann unter Delphi wieder. Da ist mir lieber, von DX9 auf OpenGL umzusatteln.
@Schrompf
Ja meine Implementierungen damals, die Welt auf der GPU zu generieren waren erschütternd. Das brachte mir eher Lags als alles andere... das Problem ist bei DX9, dass man nicht Async zurück lesen kann. Bei den Occlusion Queries geht das ja noch, aber bei dem RT holen, da muss man entweder glück haben, dass es fertig ist, oder man bekommt nen Lag reingehauen. Und manchmal haben 200 ms Wartezeit zwischendurch nicht ausgereicht um sicher zu gehen beim erstellen. Und da ich auf CPU in ähnlichen Zeiten lag, hab ich schon seit Jahren die Cluster Erstellung wieder auf CPU, allerdings MT. Klappt auch soweit ganz gut. Außer dass ich Cachen muss, weil das erstellen so langsam ist... zumal mit AO Berechnungen mir das nicht gerade einen Geschwindigkeitszuwachs bringt. Allerdings würde ich nun nochmal probieren, wie es sich mit OpenGL verhält.
Deinen Ansatz finde ich extrem gut. Und solange ich bei Shadern bin, kann ich mir das gut vorstellen mit den kleinen Aufgaben. Aber sobald ich auf der CPU arbeite krüppel ich mir da einen zusammen.
Momentan überlege ich auch, ob ich vielleicht auf lange Sicht eine reine GPU Lösung tendiere, so dass man gar nicht mehr auf CPU zurücklesen muss... sollte ja eigentlich gehen, wenn man die Eingabe über Konstanten rein gibt und dann auch die Logik und Physik komplett auf GPU läuft. Ich muss mich nur überwinden und trauen, diese ganzen Schritte zu gehen.
@dot
Ach jetzt fällt mir erst auf, dass das Bild ja logarithmisch ist... ja das ist dann natürlich extrem krass, wenn man sich das in linearer Darstellung vorstellt! :D
-
Schrompf
- Moderator
- Beiträge: 4854
- Registriert: 25.02.2009, 23:44
- Benutzertext: Lernt nur selten dazu
- Echter Name: Thomas Ziegenhagen
- Wohnort: Dresden
- Kontaktdaten:
Re: Maximale Rechenleistung
Nuja, gute Überlegungen, aber im Ernst: such Dir einen Profiler. Es gibt mit VerySleepy und Konsorten auch externe Profiler, die dann natürlich nur sample-basiert arbeiten und nur auf Basis der Debuginformationen Callstacks und so erzeugen. Ich weiß nicht, ob Delphi ein kompatibles Debuginfo-Paket erstellen kann, aber das wäre ne Idee. Profiler sind ja kein Hexenwerk, sondern im einfachsten Fall nur 1000 mal pro Sekunde ein "Wo genau im Code steckst Du gerade?". Das kann sehr erhellend sein.
Andere Idee: Landschaftsgen auf CPU und GPU gleichermaßen. Der rechenaufwändige Teil der Volumenbefüllung, Meshgenerierung und AO-Berechnung geht auf der GPU, und parallel dazu erstellst Du auf der CPU nur das Volumen für Kollisionsabfragen und sowas. Leider würde die Meshgenerierung auf der GPU mindestens DX10 und VertexOut erfordern.
Andere Idee: Landschaftsgen auf CPU und GPU gleichermaßen. Der rechenaufwändige Teil der Volumenbefüllung, Meshgenerierung und AO-Berechnung geht auf der GPU, und parallel dazu erstellst Du auf der CPU nur das Volumen für Kollisionsabfragen und sowas. Leider würde die Meshgenerierung auf der GPU mindestens DX10 und VertexOut erfordern.
Früher mal Dreamworlds. Früher mal Open Asset Import Library. Heutzutage nur noch so rumwursteln.
Re: Maximale Rechenleistung
Also mit Lazarus konnte man ganz einfach den sysprofiler benutzen. Da die Debug-Symbole in der Executable hinterlegt waren, konnte ich anschließend Prozent-genau wissen, wo die meiste Zeit verbraten wurde.
http://fedoraproject.org/ <-- freies Betriebssystem
http://launix.de <-- kompetente Firma
In allen Posts ist das imo und das afaik inbegriffen.
http://launix.de <-- kompetente Firma
In allen Posts ist das imo und das afaik inbegriffen.